Summary
Vision-Language-Action (VLA) models are a powerful recipe for general-purpose robots, but a camera cannot feel, and that is exactly what precise, contact-rich tasks demand. TacFiLM brings touch to a pretrained VLA through feature-wise linear modulation (FiLM): instead of bolting on extra tactile tokens, it lets tactile signals directly condition the model’s visual features. The result keeps the vision-language backbone intact, adds almost no inference overhead, and adapts from modest data, while improving success and force stability on hard insertion tasks. This work was done in collaboration with NVIDIA Research.
The problem with vision-only manipulation
VLA models map an image and a language instruction straight to actions, and they generalize impressively thanks to internet-scale pretraining. But whether a peg is fully seated, how much a surface grips, or whether the gripper is touching at all simply does not show up reliably in an RGB frame, and occlusion hides the contact at the very moment it matters. Visuo-tactile sensors like DIGIT close that gap with a dense image of the contact surface; the real question is how to fold that signal into a VLA without paying for it in compute, data, or stability.
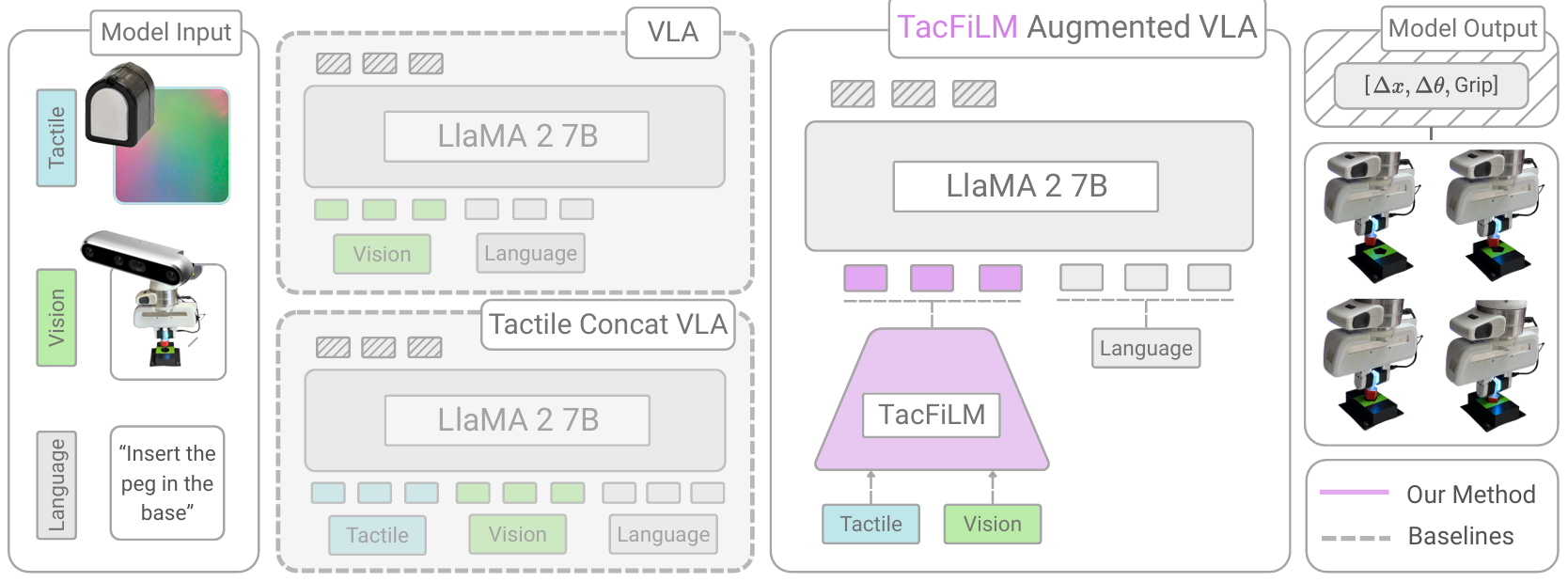
Why naive fusion is expensive
The obvious approach is to encode the tactile image into extra tokens and concatenate them to the input. It works, but it is costly where it hurts: more tokens mean longer sequences and slower inference, the reshuffled attention forces the model to relearn how to use its own visual features (demanding scarce paired tactile data), and heavy retraining erodes the very pretraining that made the VLA useful. We wanted fusion that is additive, not invasive: light on overhead, gentle on the backbone, and learnable from a handful of demonstrations.
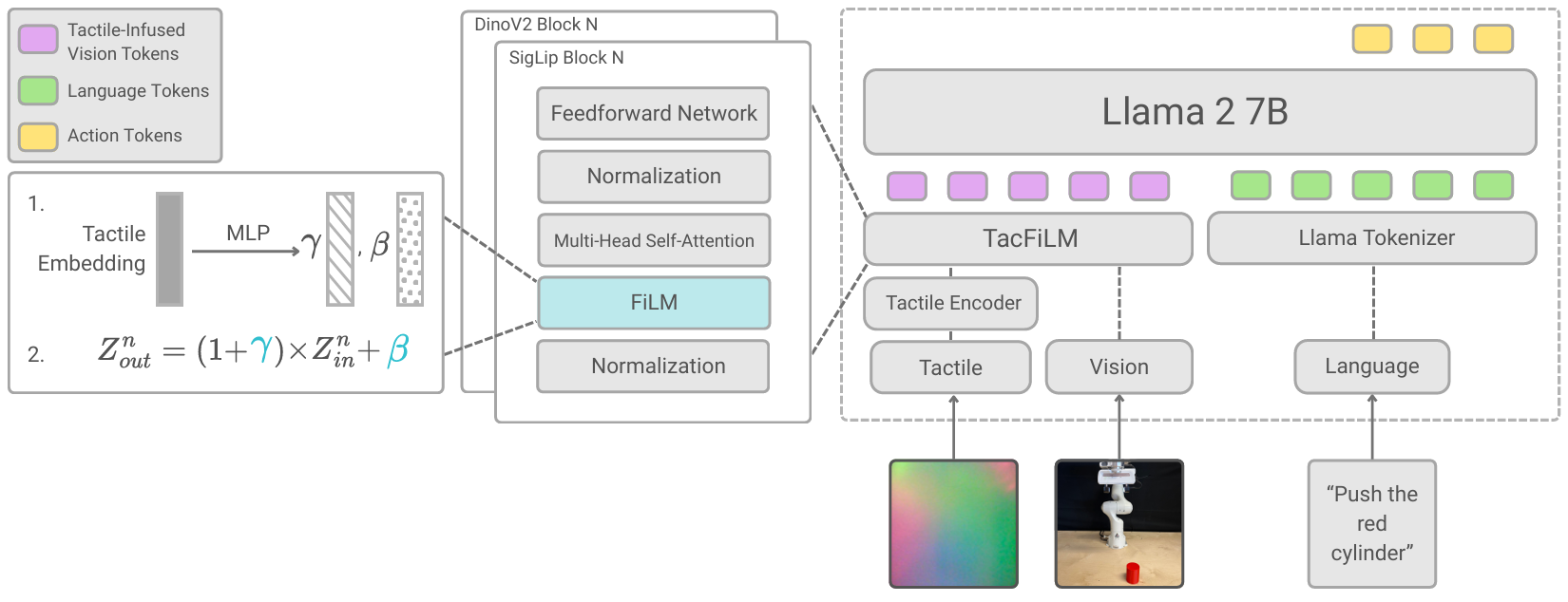
TacFiLM: conditioning vision on touch
TacFiLM integrates touch through feature-wise linear modulation (FiLM). A tactile encoder reads the contact image and predicts per-channel scale (gamma) and shift (beta) values; each visual feature is then scaled and offset accordingly. In effect, touch is allowed to reweight and bias what vision sees, amplifying what matters at contact and damping the rest, all without lengthening the sequence the transformer processes. Because we condition rather than re-architect, the OpenVLA backbone stays intact, latency barely moves, and adaptation is fast and data-efficient. We also reuse pretrained tactile encoders such as T3 and Sparsh, so TacFiLM benefits from tactile pretraining the same way the VLA already benefits from vision-language pretraining.
Results
We test TacFiLM on contact-rich insertion with a Franka Panda arm and a DIGIT sensor, the regime where vision-only policies struggle most. Conditioning on touch lifts both success rate and force stability, with the largest gains on tight-tolerance insertions where feedback carries the most information, and it does so without the cost of token-level fusion. Encouragingly, pretrained tactile encoders transfer cleanly, hinting that touch foundation models can become a reusable building block for VLAs.

Code and data will be released soon, watch this page. More media and qualitative rollouts will be added here as they become available.
Citation
@article{morissette2026tactile,
title = {Tactile Modality Fusion for Vision-Language-Action Models},
author = {Morissette, Charlotte and Abyaneh, Amin and Chang, Wei-Di and
Houssaini, Anas and Meger, David and Lin, Hsiu-Chin and
Tremblay, Jonathan and Dudek, Gregory},
journal = {arXiv preprint arXiv:2603.14604},
year = {2026}
}