Abstract
In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) 2023.
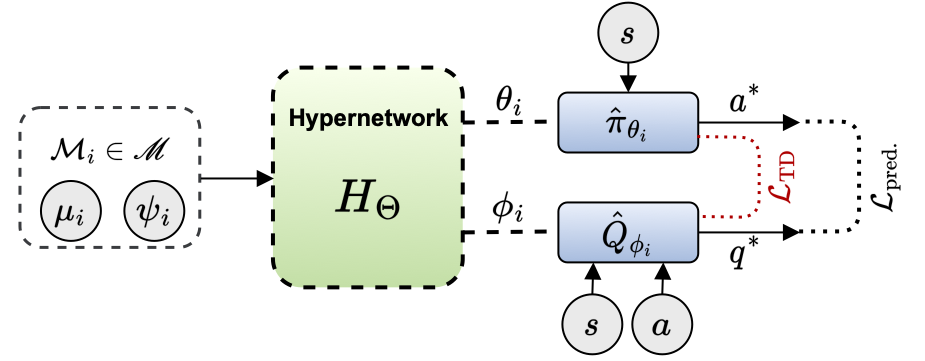
This research introduces a hypernetwork-based approach to zero-shot generalization in reinforcement learning (RL) by mapping task parameters to near-optimal policies and value functions. This allows for behaviours to be generated across a range of unseen task conditions without requiring task-specific policies. Our approach views RL algorithms as a mapping from Markov Decision Process (MDP) specifics to near-optimal value functions and policies that can be approximated by hypernetworks given the parameters of the MDP. This improves sample efficiency and generalization with implications for robotics and autonomous systems. In this work, we introduce, HyperZero, an implementation of this approach that incorporates a TD-based loss for regularization of the generated policies and value functions. Additionally, we provide a series of modular and customizable continuous control environments for transfer learning across different reward and dynamics parameters. Our results demonstrate significant improvements over baselines from multi-task and meta RL approaches. This work was conducted at the Samsung AI Center in Montréal.