Abstract
International Conference on Learning Representations (ICLR) 2026.
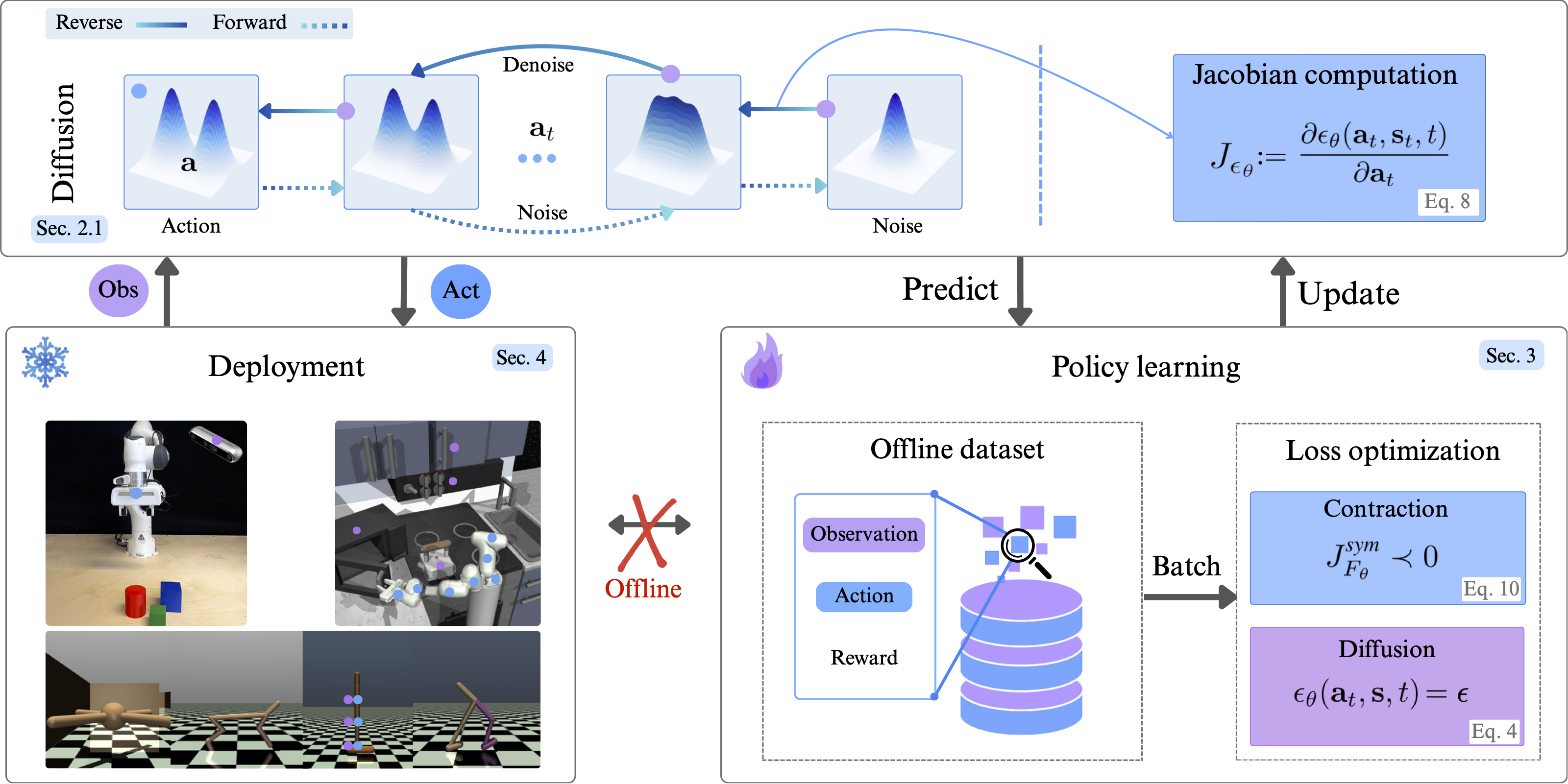
In this work, we investigate contractive behaviour in diffusion policies. These policies, defined by a learned score function that iteratively denoises corrupted action samples, often suffer from solver inaccuracies, score-matching errors, large data requirements, and inconsistencies in generated actions. In continuous control domains such as robotic manipulation, these issues can significantly degrade performance and lead to task failures. We propose contractive diffusion policies (CDPs) as a solution to this issue. This approach draws nearby flows closer together, minimizing unwanted action variance and allowing for robustness against solver and score-matching errors. We provide theoretical analysis of our contribution along with an implementation approach to integrating CPDs into existing diffusion policy architectures. Our results demonstrate improved policy learning in continuous control task and in low data regimes compared to traditional diffusion BC.