Abstract
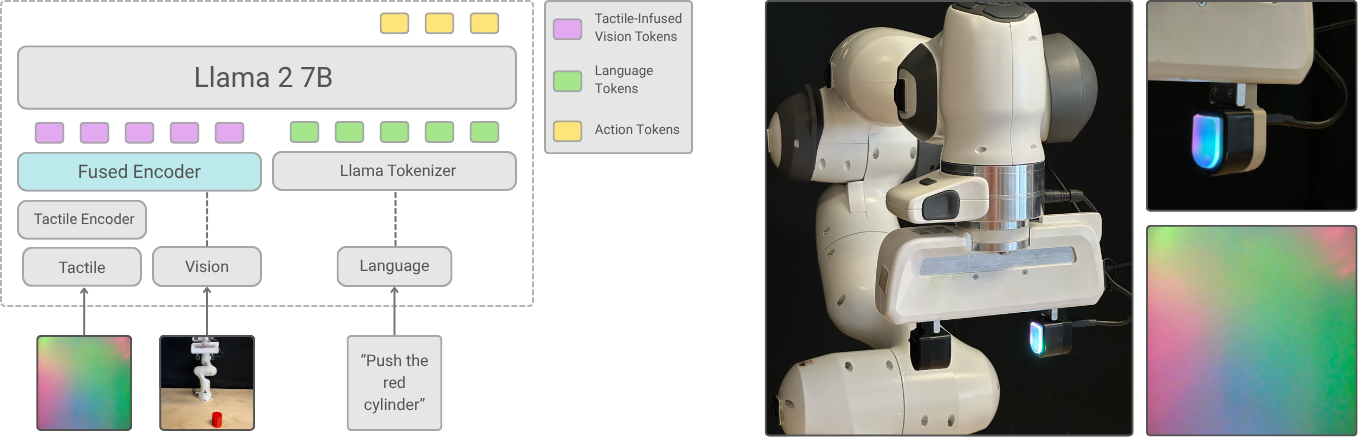
The primary objective of this research is to integrate readings from visuo-tactile sensors, such as DIGIT, into Vision-Language-Action (VLA) models, enabling proficiency in contact-rich tasks. Traditionally, VLA models map visual inputs and natural language directives to robotic actions. However, vision alone is limited in complex manipulation tasks and benefits from the additional information afforded by tactile sensors. In this project, we investigate different approaches to efficient modality fusion in VLA models and propose a tactile-augmented VLA model. Recent work has explored methods such as concatenating additional tactile tokens and contrastive learning to integrate tactile signals into VLA models. We aim to show that, our approach is parameter and compute-efficient while maintaining comparable performance. It leaves core vision-language components mostly intact, adds minimal inference overhead, and enables fast adaptation without retraining the entire model. Furthermore, this work examines the application of pre-trained tactile representations and their benefits in tactile integration into VLA models. This work is conducted in collaboration with NVIDIA Research.